Elementi software
(ovvero: quello che c'è da sapere prima del viaggio)
|
Una volta realizzato l'hardware (CPU memorie e porte di I/O)
è necessario scrivere un programma di controllo specifico per ogni
applicazione e "fissarlo" nella EPROM a partire dall'indirizzo 0, in modo
che all'accensione, o dopo un reset, il microprocessore cominci ad eseguirlo
automaticamente.
Per avere un sistema hardware e software perfettamente funzionante,
da un lato è necessario configurare e inizializzare le porte di
I/O, dall'altro è necessario configurare almeno lo stack del processore
(in circuiti più complessi può essere necessario configurare
anche la modalità di interrupt).
Al di la delle singole applicazioni si devono considerare alcuni aspetti
comuni che riguardano la rappresentazione delle informazioni, i registri
dello Z80, i flags, lo stack e la gestione degli interrupt. Alcune di queste
cose sono comuni a tutti i sistemi a microprocessore, e per poter programmare
un'applicazione è necessario conoscerle.
Rappresentazione delle informazioni
I dati elementari su cui lo Z80 può lavorare direttamente
sono i byte (gruppo di 8 bit) e le word (gruppo di 16 bit spesso suddiviso
in due byte). Un byte può rappresentare valori binari compresi tra
0 e 255, una word tra 0 e 65535.
La seguente figura mostra come viene memorizzato il valore 168 in un
registro a 8 bit o in una cella di memoria (le celle di memoria sono tutte
a 8 bit):
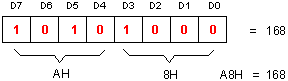
L'indicazione D0..D7 mostra su quali fili del BUS dati transitano i
vari bit del byte se questo viene inviato all'esterno della CPU o se viene
letto dall'esterno. D0 è il bit meno significativo (peso 1 o 2^0),
D7 è quello più significativo (peso 128 o 2^7). Si nota anche
la rappresentazione esadecimale, questa notazione è comoda perchè
ogni digit (o cifra) esa rappresenta esattamente 4 bit. Un gruppo di 4
bit è detto nibble, e può assumere un valore compreso tra
0 e 15 (0H..FH in esa). Un byte è perciò composto da due
nibble, uno basso (meno significativo, di peso 1 o 16^0) e uno alto (più
significativo, di peso 16 o 16^1).
La figura seguente mostra come viene memorizzato il valore 25000 nel
registro a 16 bit HL (scomponibile nei due registri a 8 bit H ed L):
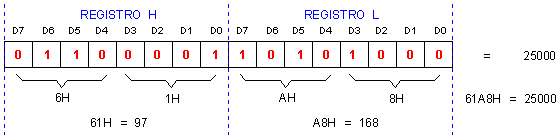
Un valore a 16 bit molto spesso viene rappresentato con due
byte, detti byte basso (meno significativo, di peso 1 o 256^0) che contiene
gli 8 bit meno significativi, e byte alto (più significativo, di
peso 256 o 256^1) che contiene gli 8 bit più significativi. In un
registro a 16 bit come HL il byte alto è memorizzato in H e quello
basso in L. Il valore 25000 si può quindi vedere scomposto nei due
valori 97 e 168: 97*256+168=25000. Scrivere LD HL,25000 oppure LD
H,97 e LD L,168 è la stessa cosa.
Il valore di un byte può rappresentare qualsiasi cosa a seconda
del contesto, può cioè essere un'istruzione del programma,
un numero binario compreso tra 0 e 255, un numero binario compreso tra
-128 e +127, un carattere alfanumerico (come la lettera A) o una parte
di un valore a 16 bit. Pur non essendoci alcuna distinzione fisica, le
informazioni in memoria generalmente si suddividono in programma e dati:
il programma sono le istruzioni per la CPU e i dati sono le informazioni
su cui il programma deve lavorare.
Le istruzioni binarie in linguaggio macchina possono essere lunghe da
uno a 4 byte (da 8 a 32 bit). Un'istruzione lunga 4 byte viene caricata
un byte alla volta in 4 passaggi e risulta perciò molto più
lenta da eseguire rispetto a una lunga un byte.
I dati a 16 bit vengono caricati o memorizzati in due passaggi, quelli
a 8 bit in uno solo.
In memoria i valori a 16 bit sono scritti memorizzando per primo sempre
il byte basso e poi quello alto. Il valore a 16 bit 25000 (che scomposto
in parte alta e bassa diventa i due byte 97 e 168) viene memorizzato come
168 e 97. Allo stesso modo scrivendo in memoria il contenuto di HL viene
memorizzato per primo il registro L e poi H.
Per rappresentare valori binari negativi si utilizza la notazione in
il complemento a 2, in pratica si invertono tutti i bit e si somma 1. Il
valore 12 a 8 bit in binario è 00001100, il -12 espresso in complemento
a 2 è 11110100. Si nota che 11110100 è anche la rappresentazione
del valore positivo 244. Quando si considerano i numeri con segno il range
dei valori rappresentabili si modifica, un byte con segno può rappresentare
valori da -128 a +127. I valori negativi vengono rappresentati da quelli
positivi da +128 a +255 considerati come negativi complementati. In alcuni
linguaggi di programmazione un byte usato in questo modo viene definito
SHORTINT (intero corto).
Per i numeri a 16 bit vale lo stesso discorso, il 4822 positivo è
00010010 11010110. Il -4822 è 11101101 00101010, che corrisponde
al valore 60714 positivo. Per i numeri a 16 bit con segno il range va da
-32768 a +32767. In alcuni linguaggi di programmazione una word usata in
questo modo viene definita INTEGER (intero).
Tutto questo discorso sul complemento a 2 significa in pratica che quando
vogliamo rappresentare un valore negativo dobbiamo scrivere l'equivalente
positivo corrispondente al suo complemento.
Un modo rapido per ottenere il valore positivo corrispondente al negativo
complementato è fare 256-valore (per i numeri a 8 bit) e 65536-valore
(per i numeri a 16 bit): 256-12=244, 65536-4822=60714. Possiamo procedere
allo stesso modo se vogliamo sapere che numero negativo corrisponde a una
certa rappresentazione in positivo: 256-244=12, 65536-60714=4822.
Rappres. BYTE Rappres
senza segno con segno
0 00000000 0
8 00001000 8
127 01111111 127
128 10000000 -128
129 10000001 -127
254 11111110 -2
255 11111111 -1
WORD
0 0000000000000000 0
8 0000000000001000 8
127 0000000001111111 127
128 0000000010000000 128
256 0000000100000000 256
32767 0111111111111111 32767
32768 1000000000000000 -32768
65534 1111111111111110 -2
65535 1111111111111111 -1
|
Questa tabella mostra come la stessa combinazione di BIT può
rappresentare numeri positivi o negativi. Per la CPU non fa differenza,
le operazioni di somma e sottrazione binaria danno il risultato corretto
sia che si considerino i valori con segno sia che si considerino senza. |
Sommare 1 a un registro a 8 bit che contiene 255 lo riporta a zero. Sottrarre
1 da un registro a 8 bit che contiene 0 lo porta a 255.
Sommare 1 a un registro a 16 bit che contiene 36635 lo riporta a zero.
Sottrarre 1 da un registro a 16 bit che contiene 0 lo porta a 65535.
Se occorre rappresentare numeri più grandi di quelli contenibili
nei registri occorre usare delle celle di memoria di tanti byte quanti
ne servono per rappresentare il nostro valore. E'ovvio che in questo caso
un elaborazione del valore (ad esempio una somma) va realizzata un passo
per volta dal programma, in quanto la CPU non la può gestire direttamente.
Alcuni linguaggi di programmazione per esempio mettono a disposizione
variabili di tipo LONGINT (intero lungo). Queste rappresentano valori binari
con segno usando 4 byte e il range disponibile va da -2147483648 a +2147483647.
L'unica facilitazione verso tipi diversi di formato riguarda la rappresentazione
BCD, per la cui manipolazione lo Z80 dispone di 3 istruzioni specifiche
(DAA RRD e RLD).
Nella rappresentazione BCD i due nibble di un byte possono assumere
un valore compreso tra 0 e 9. Il nibble meno significativo ha peso 1 (o
10^0), quello più significativo ha peso 10 (o 10^1). Usando il formato
BCD un byte può contenere un valore compreso tra 0 e 99. Questo
modo di rappresentare i valori è comodo perchè ad ogni nibble
corrisponde una cifra decimale, ad esempio per rappresentare il numero
416897 occorrono 6 nibble (3 byte):

Per la precisione questa rappresentazione è detta BCD packed
(impaccata) perché ogni byte contiene due digit decimali. Un'alternativa
è la rappresentazione BCD unpacked (non impaccata), in cui ciascun
byte contiene solo un digit di valore compreso tra 0 e 9 (per rappresentare
il 416897 occorrerevvero perciò 6 byte). Le istruzioni dello Z80
valgono solo per la rappresentazione packed.
Di una cella di memoria o di un registro si possono testare o modificare
i singoli bit con le istruzioni SET (setta un bit), RES (resetta),
BIT
(testa il bit e setta il flag Z se il bit è a zero).
La rappresentazione dei caratteri alfanumerici (lettere, simboli di
interpunzione, e numeri intesi come caratteri e non come valori) si basa
sul rappresentare ogni carattere con un valore ben preciso. Il codice ASCII
ad esempio stabilisce che la lettera A maiuscola viene rappresentata dal
valore 65.
Nello stesso modo una volta stabilita l'adeguata convenzione, i byte
possono essere usati per rappresentare virtualmente qualsiasi tipo di informazione
(anche se dal punto di vista fisico per la CPU ci sono solo numeri da 0
a 255 indifferenziati).
I Registri dello Z80
Il microprocessore dispone al suo interno di un certo numero di registri,
in cui si possono memorizzare dei valori binari a 8 o 16 bit, e con cui
si possono eseguire delle operazioni logiche o aritmetiche.
Alcuni di questi registri sono a disposizione del programmatore e la
CPU non li tocca (evidenziati in verde nella tabella seguente), altri come
il program counter (PC) e il refresh register (R) sono gestiti dalla CPU
per il proprio funzionamento.
Sulla destra c'è il set alternativo, è una copia dei registri
generali che può essere usata per un rapido salvataggio/ripristino.
Non sono colorati per indicare che il loro valore è inaccessibile
quando si sta usando l'altro set.
SET PRINCIPALE
A
(accumulatore) |
F
(flag) |
| B |
C |
| D |
E |
| H |
L |
|
SET ALTERNATIVO
A'
(accumulatore) |
F'
(flag) |
| B' |
C' |
| D' |
E' |
| H' |
L' |
|
| IX |
| IY |
SP
(puntatore allo stack) |
PC
(contatore di programma) |
I
(vettore interrupt) |
R
(rinfresco memoria) |
|
|
A: registro accumulatore a 8 bit, è un registro privilegiato
in quanto è l'unico che può ricevere il risultato di diverse
operazioni aritmetiche e logiche.
BC DE HL: registri a 16 bit di uso generale, possono essere usati
come 6 registri a 8 bit: B C D E H L. Se si utilizza l'istruzione
DJNZ
il registro B è usato come contatore a 8 bit. Il registro
HL
è il registro privilegiato a 16 bit (come
A lo è tra
quelli a 8), in quanto è l'unico che può ricevere il risultato
di alcune operazioni o essere usato in alcune istruzioni.
IX IY: registri indice a 16 bit, sono specializzati per essere
usati nelle istruzioni di accesso indicizzato, come ad esempio LD A,(IX+12).
Le istruzioni che li usano sono le più lente da eseguire.
SP: puntatore alla "testa" dello stack, cioè all'ultimo
elemento memorizzato sullo stack.
PC: program counter, punta sempre all'indirizzo della prossima
istruzione da eseguire, è gestito dall'hardware del processore e
non può essere modificato direttamente. All'accensione viene impostato
a zero, e questo è infatti l'indirizzo a cui la CPU cerca la prima
istruzione da eseguire.
F: registro dei flag, non può essere modificato direttamente.
I singoli bit di questo registro sono modificati dal processore in accordo
con i risultati delle diverse operazioni aritmetico logiche del programma
e servono per "prendere delle decisioni" ed effettuare i salti condizionati
(come JRZ JRC ecc...)
I e R: registri legati all'uso delle interruzioni modo
IM
2 e al rinfresco delle memorie dinamiche, in circuiti semplici possono
essere ignorati. Tuttavia se non si usa il modo interrupt IM 2 il
registro I può essere usato come ulteriore registro generale
per salvare il valore di A. Il registro R invece si incrementa
automaticamente ad ogni istruzione eseguita e varia ciclicamente da 0 a
255, se non sono collegate memorie dinamiche la sua presenza è inutile,
salvo che non lo si voglia usare per ottenere dei valori pseudo casuali.
Il set alternativo dei registri generali consente un rapido salvataggio/ripristino
dei loro valori. Con EX AF,AF' si scambiano A ed F
con A' ed F', con EXX si scambiano BC DE HL
con BC' DE' HL'.
Non si devono vedere i registri della CPU come le variabili di un qualsiasi
altro linguaggio di programmazione, anche se per operazioni molto semplici
possono essere usati in questo modo. Se si devono memorizzare molti valori
di lavoro si devono usare delle celle di memoria, e ciascuna di esse può
all'incirca essere considerata come una variabile di tipo byte. I registri
servono per manipolare le informazioni e spostarle avanti e indietro dalla
memoria.
Volendo la memoria può anche essere pensata come un enorme insieme
di registri privi di nome ma contrassegnati da un numero (indirizzo) da
0 a 65535. E' evidente che i diversi valori su cui il programma lavora
è meglio sistemarli in questo insieme di "registri di deposito",
piuttosto che nei registri principali della CPU che sono pochi e servono
per eseguire i singoli passi elementari del programma. Però è
anche vero che le istruzioni che richiedono l'accesso a valori in memoria
sono molto più lente di quelle che coinvolgono i soli registri interni.
Nel caso che l'applicazione richieda la massima velocità è
quindi utile cercare di fare il più possibile solo con i registri.
Ad esempio se si deve caricare molte volte in A un certo valore, mettiamo
26, e rimane un registro a 8 bit libero, mettiamo E, allora piuttosto che
fare molte volte LD A,26 è meglio caricare in E il valore e successivamente
fare molte volte LD A,E risparmiando 3 cicli di clock per ogni sua esecuzione.
Se questa istruzione si trova all'interno di un ciclo di 5000 iterazioni
il risparmio totale è di 15000 cicli di clock (3,75 millisecondi
a 4 Mhz). Può sembrare un tempo irrisorio, ma se un sistema real
time deve per esempio eseguire tutte le sue elaborazioni almeno 100 volte
al secondo, allora ha solo 10 millisecondi di tempo per farlo, e 3,75 millisecondi
risparmiati possono fare la differenza.
I flags
I flags (o bandiere) sono degli indicatori che la CPU alza
o abbassa a seconda del verificarsi di certe condizioni. I flags fisicamente
sono i bit del registro F. Ciascuno di essi indica una condizione ben precisa
e ha un nome che ne ricorda il significato:

I due flags più importanti che si usano comunemente sono il flag
di zero e quello di carry (o riporto). Il flag di zero viene settato se
il risultato di un'operazione aritmetica o logica è zero, quello
di carry se il risultato genera un riporto (nel caso della somma) o un
prestito (nel caso della sottrazione).
I flags sono modificati anche da diverse altre istruzioni, tra cui quelle
di confronto (CP CPI CPIR ecc...). E' grazie al valore che assumono
i flags dopo una di queste operazioni che possiamo stabilire se un numero
è maggiore minore o uguale a un altro.
Una istruzione di confronto effettua sempre una sottrazione tra l'accumulatore
A
e il valore da confrontare (che può anche essere un altro registro).
Per esempio CP B significa "confronta il valore di A con il valore
del registro B". La sottrazione che viene effettuata è A-B,
il valore di A alla fine non viene cambiato ma vengono impostati i flags
in accordo con il risultato della sottrazione.
E' chiaro che se il valore di B è maggiore di A verrà
generato un prestito, e quindi verrà settato il flag C. Se invece
il valore di B è uguale ad A il risultato della sottrazione è
zero, e verrà settato il flag Z. Se invece il valore di B è
minore di A nessuno dei due flag verrà settato.
CP B
(A - B) |
| B > A |
C=1 Z=0 |
| B = A |
C=0 Z=1 |
| B < A |
C=0 Z=0 |
|
Questa tabella mostra come
vengono settati i flags a seconda
del valore di B rispetto ad A |
Il valore dei flags può essere usato da quelle istruzioni che prevedono
una condizione come ad esempio JR C JP NZ CALL NC
RET Z ecc...
La condizione Z significa "se il flag zero è settato"
(a 1), la condizione NZ significa "se il flag zero è resettato"
(a 0). Analogamente C e NC indicano il flag C settato o resettato.
L'istruzione JP NC,indirizzo significa: salta a "indirizzo" se il
flag C non è settato (occhio a non confondere il flag C con il registro
C!).
A - B |
| B > A |
C |
| B < A |
NC e NZ |
| B = A |
Z |
| B <> A |
NZ |
| B >= A |
C o Z |
| B <= A |
NC |
|
Questa tabella mostra le condizioni
verificabili controllando i flags C e Z.
Con le istruzioni di salto condizionato
si può realizzare l'equivalente dell'
IF THEN GOTO in BASIC.
NC e NZ indicano la condizione opposta
a C e Z: se Z è settato, allora la condizione
NZ è falsa, se Z è resettato allora la
condizione NZ è vera. |
Lo stack
Lo stack è un'area di memoria RAM destinata alla memorizzazione
temporanea di dati e indirizzi gestita direttamente dal processore, è
necessaria per salvare gli indirizzi di ritorno per le subroutine (chiamate
con CALL indirizzo e terminanti con RET) ed eventualmente
dei dati temporanei di lavoro, spinti sullo stack con le istruzioni PUSH
e prelevati poi con le istruzioni POP.
Per configurare lo stack è sufficiente scrivere all'inizio del
programma l'istruzione LD SP,indirizzo, dove indirizzo è
la posizione iniziale in memoria che si vuole dare allo stack.
Lo stack, ad ogni salvataggio di dati (o chiamata di subroutine), cresce
verso il basso di 2 byte, in altre parole: se inizializziamo ad esempio
lo stack a 65000, allora al primo salvataggio dati vengono scritti due
byte nelle celle di indirizzo 64999 e 64998 e il valore dello stack pointer
(registro SP) decrementa di 2. Al successivo salvataggio vengono
memorizzati altri due byte in 64997 e 64996 e SP decrementa ancora di
2. Poi, al momento opportuno i dati salvati vengono recuperati e SP incrementa
di 2 in 2 tornando alla fine al valore iniziale.
Lo stack è quindi un'area di memoria che può essere occupata
dinamicamente durante l'esecuzione del programma e si espande dal valore
inizialmente impostato verso indirizzi più bassi.

Di quanto si espande? Dipende dal programma, ogni CALL nidificata aggiunge
2 byte sullo stack, ogni PUSH altri 2. Se ipotizziamo 3 chiamate a subroutine
nidificate che salvano ciascuna 5 dati (10 byte) occupiamo 36 byte. In
genere un'area di 100 byte è più che sufficiente, per scrupolo
possiamo considerarne 200. Si può allora inizializzare lo stack
in cima alla RAM (all'ultimo indirizzo 65535) e considerare occupati gli
ultimi 200 byte, dopo di che allo stack non ci si pensa più.
Si può fare a meno dello stack? Certo, però non si possono
più usare le subroutine, il processore non può rispondere
agli interrupt e non si possono salvare/recuperare i dati con le istruzioni
PUSH e POP. A proposito di questo è importante ricordare che lo
stack è una struttura LIFO (last in first out), il che significa
che i dati si prelevano dallo stack in ordine esattamente opposto a come
sono stati scritti, per primo si preleva l'ultimo scritto, proprio come
una pila di piatti appoggiati l'uno sopra l'altro che si iniziano a prendere
dall'ultimo appoggiato. Alla fine il numero di POP (recupero dallo stack)
deve euguagliare il numero di PUSH, come il numero di RET (ritorni da subroutine)
deve euguagliare il numero di CALL (chiamata di subroutine). Dimenticare
un dato nello stack all'interno di una subroutine manda sicuramente in
crash il sistema, in quanto il processore non è più in grado
di trovare gli indirizzi di ritorno corretti e viene dirottato a indirizzi
di memoria casuali.
Gli interrupt
Lo Z80 dispone di due pin INT e NMI grazie ai
quali può rispondere a delle "richieste di interrupt" da parte di
dispositivi esterni. Fisicamente un segnale di interrupt è un livello
logico 0 della durata di qualche microsecondo applicato su uno dei due
pin. Questo impulso provoca la sospensione del programma in corso e l'avvio
di una subroutine di gestione dell'interrupt (detta ISR, interrupt service
routine).
L'interrupt NMI non è mascherabile (è sempre abilitato)
e viene sempre e comunque preso in considerazione dalla CPU che sospenderà
il programma principale e salterà alla locazione di memoria 102
(66H). A questo indirizzo deve esserci la prima istruzione della routine
di gestione, questa routine deve terminare con l'istruzione RETN.
L'interrupt INT è invece mascherabile (disabilitabile) via software,
per abilitarlo si utilizza l'istruzione EI, per disabilitarlo l'istruzione
DI.
All'accensione o dopo un reset la CPU si pone automaticamente in modalità
disabilitata e ogni impulso su questo pin viene ignorato.
L'interrupt INT dispone inoltre di 3 modalità di funzionamento
(impostabili con le istruzioni IM 0 IM 1 IM 2). La modalità
1 è la più semplice da gestire: quando arriva un impulso
su INT la CPU sospende il programma principale e salta all'indirizzo 56
(38H). Le altre 2 modalità richiedono invece dell'hardware esterno
aggiuntivo in grado di inviare dei dati alla CPU quando questa segnala
l'accettazione dell'interrupt. Sono due modalità che possono rendere
la risposta agli interrupt più veloce se ci sono molte periferiche
che possono generare interrupt, in circuiti più semplici è
inutilmente complicato usarle.
Per poter usare INT si deve quindi dare prima l'istruzione IM 1,
e poi EI. All'indirizzo 56 deve esserci la prima istruzione della
routine di gestione, che deve terminare con le due istruzioni EI
e RETI.
IL motivo per cui prima di RETI si deve dare di nuovo EI sta nel fatto
che quando lo Z80 accetta un INT si pone automaticamente in modo disabilitato
per evitare che la persistenza del segnale INT generi un'infinità
di interrupt a catena. Il pin INT è infatti sensibile al livello
e non al fronte di discesa.
Se al termine della routine di gestione (dopo il RETI) il livello di
INT è ancora basso allora la routine di gestione viene chiamata
un'altra volta e così via. Per questo è anche importante
che la durata dll'impulso di INT non sia troppo lunga. Ma non deve essere
neppure troppo corta perchè il livello di INT non è controllato
con continuità dalla CPU. Il suo valore viene controllato (campionato)
all'inizio dell'ultimo ciclo di clock di ogni istruzione eseguita, pertanto
per essere sicuri che la CPU "veda" l'impulso su INT, questo deve durare
almeno quanto una delle istruzioni più lente (23 cicli di clock:
5,75 microsecondi su uno Z80 a 4 Mhz).
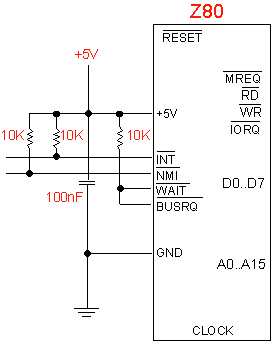 |
Per poter usare gli interrupt è necessario scollegare i pin
INT e NMI da WAIT e BUSRQ che negli schemi elettrici delle altre pagine
sono collegati e bloccati a 1 tutti assieme. INT e NMI devono ovviamente
essere bloccati a 1 con una propria resistenza di pull up da 10 Kohm: |
Durante l'esecuzione di una routine di NMI ogni altro impulso su NMI viene
ignorato e ogni altro impulso su INT viene ignorato e perso. Se è
indispensabile non perdere neppure un impulso di INT allora si deve usare
un flip flop esterno. In questo caso gli interrupt che arrivano al flip
flop sono sentiti non come livello ma come fronte di discesa:
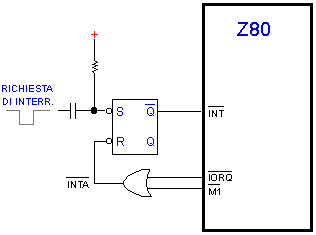
Due parole sui segnali INTA e M1. Il segnale M1 indica che la CPU sta
eseguendo il ciclo macchina 1, che corrisponde al caricamento dalla memoria
del primo byte di ogni istruzione. Quando la CPU si accorge che c'è
una richiesta di interrupt su INT, invece di caricare la prossima istruzione
attiva il segnale IORQ (come se dovesse accedere a una porta) assieme a
M1. La combinazione in OR di questi due segnali genera l'INTA (interrupt
acknowledge), che nel nostro caso serve per resettare il flip flop (nel
caso invece si usino le modalità IM0 o IM2, INTA indica all' hardware
esterno di inviare i dati per la gestione dell'interrupt).
NOTA: la costante di tempo del circuito RC che comanda il flip
flop deve essere al massimo di un microsecondo, altrimenti lo Z80 potrebbe
generare l'INTA mentre il pin S del flip flop è ancora a zero.
Affinchè le routine di gestione degli interrupt non interferiscano
con il programma principale, è necessario che, prima di ogni altra
operazione, salvino il contenuto dei registri in memoria (tipicamente con
una serie di PUSH). Al termine questi valori devono essere ricaricati nei
registri per ripristinare lo stato iniziale (tipicamente con una serie
di POP). Le istruzioni RETI e RETN concludono le due routine e fanno ripartire
il programma principale dal punto in cui era stato interrotto.
Una routine di gestione interrupt deve terminare nel più breve
tempo possibile per non rallentare troppo il programma principale, e comunque
prima che arrivi un eventuale altro impulso di interrupt che altrimenti
sarebbe perso (a meno di non usare il flip flop esterno).
.ORG 0
JP START
.DB 0,0,0,0,0,0,0,0,0,0
.DB 0,0,0,0,0,0,0,0,0,0
.DB 0,0,0,0,0,0,0,0,0,0
.DB 0,0,0,0,0,0,0,0,0,0
.DB 0,0,0,0,0,0,0,0,0,0
.DB 0,0,0
JP INT
.DB 0,0,0,0,0,0,0,0,0,0
.DB 0,0,0,0,0,0,0,0,0,0
.DB 0,0,0,0,0,0,0,0,0,0
.DB 0,0,0,0,0,0,0,0,0,0
.DB 0,0,0
;-------------------------------
; GESTORE NMI A 66H
;-------------------------------
......
......
......
RETN
;-------------------------------
; GESTORE INT CHIAMATO DA 38H
;-------------------------------
INT ......
......
......
EI
RETI
;-------------------------------
; PROGRAMMA PRINCIPALE
;-------------------------------
START LD SP,65535
......
IM 1
EI
......
......
|
Qui a fianco è mostrato un esempio di inizio programma
da caricare nella EPROM all'indirizzo 0 in grado di utilizzare entrambi
gli interrupt. Visto che tra l'indirizzo 0 e 38H e tra 38H e 66H ci sono
poche decine di byte di distanza è improbabile poter scrivere una
qualche applicazione in così poco spazio, d'altra parte i segnali
di interrupt "dirottano" il processore proprio agli indirizzi 38H e 66H,
la cosa più semplice è quindi quella di piazzare nei punti
strategici delle istruzioni di salto, lunghe solo 3 byte, che dirottano
ulteriormente la CPU verso le routine applicative vere e proprie.
La prima istruzione, all'indirizzo 0, è un JP START, il codice
oggetto è lungo 3 byte (C3XXXX dove XXXX sarà l'indirizzo
di partenza della routine START), seguono 53 byte a 0 che arrivano a occupare
la memoria fino all'indirizzo 55, in 56 (38H) abbiamo l'arrivo per l'INT
e troviamo un altro jump che dirotta il processore verso la vera routine
di gestione di INT, seguono altri 43 byte a 0 che occupano fino all'indirizzo
101, a 102 infine inizia la routine di gestione di NMI, tutte le sezioni
possono a questo punto essere lunghe quanto serve.
Si nota all'inizio della sezione START l'impostazione dello stack e
l'abilitazione degli interrupt mascherabili. |
NOTA: I 53 byte tra il primo e il secondo jump e i 43 tra il secondo
e l'inizio del gestore di NMI possono anche contenere delle stringhe ASCII
con informazioni relative alla versione del programma e al copyright, che
apparirebbero in chiaro visualizzando il contenuto della EPROM con un programmatore/lettore
di EPROM.
Microesempio e "attrezzi"
Pe iniziare il lavoro il programmatore deve conoscere esattamente
le risorse fisiche disponibili, in pratica come è fatto il sistema:
i registri, le celle di memoria, gli indirizzi delle porte, l'allocazione
dello stack, gli indirizzi di partenza dei gestori di interrupt.
Nel caso del semplice modulo con 32K di ROM, 32K di RAM, 8 ingressi
e 8 uscite presentato nella pagina collegamento
I/O 1, le cose sono molto semplici: dall'indirizzo 0 della ROM in poi
mettiamo i byte del programma, la RAM è tutta sfruttabile dall'indirizzo
32768 a 65535 (salvo un'area alla fine per lo stack che possiamo considerare
contenuta in 200 byte), le porte di I/O rispondono all'indirizzo 0 e possiamo
usare tranquillamente i registri A B C D E H L IX e IY. Non vengono usati
gli interrupt e non dobbiamo preoccuparci di nient'altro perchè
tutto funzionerà correttamente.
Come esempio supponiamo di voler scrivere un programma che tutto quello
che deve fare è scrivere il valore 48 nella cella di memoria 50000.
Possiamo usare le due istruzioni LD HL,50000 e LD (HL),48,
che significano carica in HL il valore 50000 e carica nella cella di memoria
puntata da HL il valore 48 (scrivere 48 o 00110000B o 30H è la stessa
cosa).
In eprom possiamo caricare il programma:
LD HL,50000
LD (HL),48
HALT
All'accensione verranno eseguite le due istruzioni di caricamento e poi
l'istruzione HALT che ferma la CPU (perchè in questo caso non c'è
più niente altro da fare).
Naturalmente nella EPROM non scriviamo le istruzioni in questo formato
mnemonico, le dobbiamo prima convertire nel vero e proprio linguaggio macchina,
o codice eseguibile (a questo di solito ci pensa l'assemblatore, ma volendo
possiamo anche fare un assemblaggio manuale).
L'istruzione LD HL,50000 è codificata dai tre byte 21H
50H e C3H, LD (HL),48 dai due byte 36H e 30H, e l'istruzione HALT
dal byte 76H. Possiamo dire che in esadecimale questo programma è:
21 50 C3 36 30 76, in decimale: 33 80 195 54 48 118 e in binario: 00100001
01010000 11000011 00110110 00110000 01110110. Questi sono i veri valori
che vanno caricati a partire dall'indirizzo 0 della EPROM.
Per curiosità possiamo anche calcolare quanto tempo impiega la
CPU ad eseguire questo programma di 6 byte. La prima istruzione richiede
10 cicli di clock, la seconda altri 10 e l'HALT 8, per un totale di 28
cicli. Supponendo di usare un clock di 4 Mhz la durata del programma risulta
di 7 microsecondi.
Uno Z80 a 4 Mhz esegue infatti mediamente un'istruzione ogni 2..2,5
microsecondi, il che vuol dire circa 440000 istruzioni al secondo. Di questa
prestazione si deve tenere conto quando si progettano sistemi in real time
che devono "reagire" in pochi millisecondi, in un millisecondo lo Z80 non
può eseguire più di 400..500 istruzioni.
Detto questo rimane da dire che se non si vuole ricorrere al lungo e
noioso (ma estremamente didattico) assemblaggio manuale, occorre usare
un programma assemblatore, che accetta un file di testo sorgente con le
istruzioni scritte in linguaggio mnemonico, e le converte in un file eseguibile.
Inoltre si deve disporre di un programmatore di EPROM per poter trasferire
il codice oggetto nelle celle della EPROM.
Poi, visto che usando questo linguaggio di basso livello è molto
facile commettere errori, è necessario disporre anche di un cancellatore
di EPROM (lampada a ultravioletti).
Il top è un emulatore di EPROM, che dispone di un connettore
da innestare direttamente sullo zoccolo della EPROM del processore. La
CPU vede l'emulatore come se fosse la vera EPROM, con la differenza che
nell'emulatore possiamo scrivere e riscrivere rapidamente quante volte
vogliamo.
Una volta ottenuto il programma corretto lo si può poi fissare
nella EPROM definitiva.
Un'alternativa all'emulatore è quella di usare una finta EPROM
costruita con una RAM statica sempre alimentata da una batteria. Costruendo
opportunamente il circuito si può programmare la RAM con il programmatore
di EPROM e poi innestarla sullo zoccolo della EPROM del processore. Anche
in questo caso la CPU vedrà la RAM a batteria come se fosse la vera
EPROM.
Pagina e disegni realizzati
da Claudio Fin